DreamCoder: Growing generalizable, interpretable knowledge with wake-sleep Bayesian program learning
Introduction
- One goal of AI: build a machine that learns like a child that grows into all adult knowledge starting from less
- Humans have better generalization capabilities / are less data-intensive
- Goal of project: efficiently discovering interpretable, reusable, and generalizable knowledge across a broad range of domains
- Uses “wake-sleep Bayesian program induction”
- Program induction: Automatically generating a program that satisfies a given specification
- Why program induction:
- Strong generalization properties
- So learning is sample-efficient
- Expose knowledge that can be re-used and composed to solve other tasks
- Universal: any Turing-complete language can solve any problem
- What the programming language specifies:
- Hypothesis space
- Priors: shorter programs are better
- This means previous systems use a domain-specific language (DSL) with a strong, hand-tuned prior.
- Additionally, they use a hand-designed search algorithm
- What DreamCoder does:
- Learns to represent problems in programming language
- Learns to induce programs
- Learns via growing two distinct kinds of domain expertise:
- Explicit declarative knowledge
- Implicit procedural knowledge, in the form of a neural network that guides how to use the learned language to solve new tasks
- Learns both in a self-supervised, bootstrapping fashion; growing them jointly across repeated encounters with a set of training tasks
Wake / Sleep Program Learning
- Wake phase:
- Searches for programs that solve tasks drown from a training set
- Guided by neural recognition model, which ranks candidate programs based on the observed data
- Scored according to how well they solve the presented tasks, and how plausible they are given priors
- Sleep phase 1: Abstraction
- Grow the library of programming primitives
- Do this by replaying experiences from waking
- Find common program fragments
- Abstract these out as new program primitives
- Sleep phase 2: Dreaming
- Improves the procedural skill in code-writing by training a neural network that helps search for programs
- Trained on replay
- Also trained on “fantasies” – programs sampled randomly from the learned library as a generative model
- These random programs define tasks which the system solves during the dream phase; trained to predict the solutions given observable data
- As an inference problem:
- Observes a training set of tasks $X$
- Infers program $\rho_x$ solving each task $x \in X$
- Also infers a prior distribution over programs likely to solve the tasks in the domain
- This prior is encoded by a library $L$ which defined a generative model $P[\rho \mid L]$
- The neural network helps to find programs solving a task by predicting an approximate posterior distribution given the observations
- Thus, the network is a recognition model
- $Q(\rho \mid x)$ for the approximate posterior predicted by the recognition model
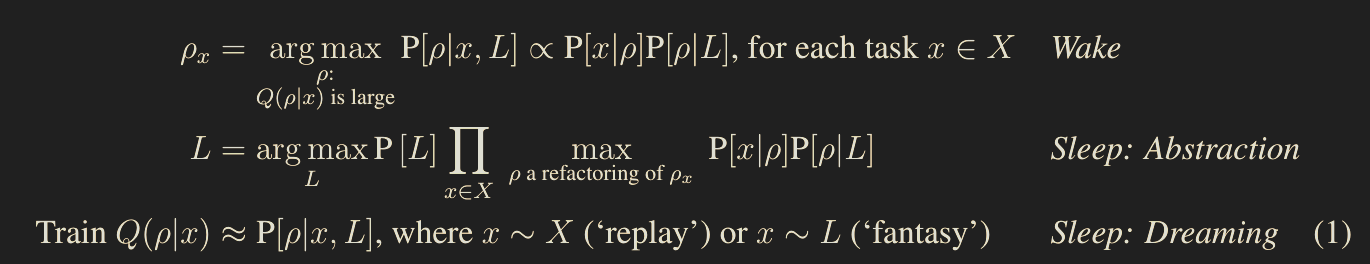
where
- $P[L]$ is the description-length prior over libraries. This specifically means $\propto 2^{-\text{length}}$ across all code defined in the library’s primitives
- $P[x \mid \rho]$ is the likelihood of a task $x \in X$ given $\rho$
The generative and recognition models bootstrap each other:
- A more specialized library yields richer dreams
- A more accurate recognition model solves more tasks during waking
Search efficiency:
- Better libraries reduce the depth of search, since we have better primitives
- Better recognition models reduce the breadth of search since poor programs are downweighted
Wake Phase
- Sample a random minibatch of tasks and observational data
- Search for programs solving these tasks by
- Enumerating programs in decreasing order under $Q(\rho \mid x)$
- Checking if $P[x \mid \rho]>0$
- Keep the top $k = 5$ programs with the higher $P[\rho \mid x, L]$
- Program of choice: polymorphically typed lambda calculus
Abstraction Phase
- Goal is to expand their library of concepts
- More specifically minimize the sum of
- Description length of the library $-\log P[D]$
- Description lengths of refactors $$\sum_x \min_{\rho \text{ refactors }\rho_x}\left(-\log P[x \mid \rho] \cdot P[\rho \mid D]\right)$$
- More specifically, this is similar to abstracting away duplicate code but instead of duplicate code you abstract away semantically equivalent code that is syntactically different
- Bounds the number of $\lambda$-calculus evaluation steps separating a program from its refactoring
- Many possible refactorings, $10^{14}$. Grows exponentially in program size and evaluation steps
- Created a data structure for representing and manipulating refactorings which cuts this down to $10^6$
Dreaming Phase
- Training the neural network using domain-specific architecture
- E.g., when inducing graphics programs from images, use a convolutional network
- Data:
- Replays of programs discovered during waking
- Fantasies on programs drawn from $L$
- Replays ensure the recognition model is trained on actual tasks it needs to solve
- Typically train on 100-200 tasks
- Naive way to dream:
- Sample a random program from the generative model
- Execute it to generate a task
- Train the recognition network to predict the sampled program from the sample task
- Instead:
- Create an endless stream of random problems
- Solve using the sleep procedure
- Use the solved programs
- Why: this gets a canonical form of equivalent programs
- Then $Q$ is trained to predict the solutions discovered, conditioned on the problems
- More specifically:
- Maximize $$\mathbb{E}\left[\log Q((\arg \max_\rho P[\rho \mid x, L]) \mid x)\right]$$
- Trained on 50/50 mix of replays and fantasies
- For fantasies mapping inputs to outputs, sample inputs from the training tasks
- MAP approach: finds a simple canonical solution for each problem
Results
Two benchmarks:
- List processing:
- 218 tasks
- Split 50/50 train/test
- Specified by 15 input-output examples over lists of integers
- E.g., sort a list, double each element, etc.
- Text editing:
- 128 automatically-generated training tasks
- Tested on 108 problems from the 2017 SyuS program synthesis competition
- Each task is a string transformation specified by input-output examples, such as “Alan Turing” -> “A.T.”
- For automatically generated tasks:
- Main conclusions:
- Learned
Library Implementation Details
The library consists of
- $D$, a set of expressions in $\lambda$-calculus. This is the discrete structure
- A vector $\theta$ representing weights, with dimensionality $|D|+1$. The extra dimension covers all bound variables
- Then $L = (D, \theta)$
- We can write the join distribution $$J(D, \theta) = P[D, \theta] \cdot \prod_{x \in X} \sum_{\rho} P[x \mid \rho]\cdot P[\rho \mid D, \theta]$$ We can find the optimal library via $$D^* = {\arg \max}_{D} \int J(D, \theta) \cdot d\theta$$ $$\theta^* = {\arg \max}_{\theta} J(D^*, \theta)$$
def sample(D, theta, tau):
# outputs a program whose type unifies with type
return sample'(D, theta, {}, type)
def sample'(D, theta, env, type):
if tau = a -> b:
var = unused var name
body ~ sample'(D, theta, {var: alpha} \cup env, beta)
return (lambda (var) body)
else:
primitive = {p | p : tau' \in D \cup env if tau can unify with yield(tau')}
variable = {p | p is primitive and p a variable}Version Space Data Structure
A version space is either
deBuijn index: an alternative way of naming variables in $\lambda$-calculus. $\lambda$-abstractions are written without a variable name, and variables are written as the count of the number of $\lambda$-abstractions up in the syntax tree the variable is bound to.
E.g., $\lambda x. \lambda y.(x y)$ is written $\lambda \lambda (\$1 \ $0)$
An abstraction: $\lambda v$, where $v$ is a version space
An application $(f \ x)$
A union $\cup V$ where $V$ is a set of version spaces
The empty set $\varnothing$
The set of all $\lambda$-calculus expressions
Biggest Observations
- It seems like this architecture is capable of genuinely learning new knowledge in a way that LLMs aren’t obviously capable of (i.e., tree-search style thinking)
- LLMs generate knowledge via searching for best weights, which takes longer and longer with more weights. Meanwhile, this generates knowledge via some kind of tree search on programming primitives, which in theory should be faster.
- Gives a formal def’n of world model
- The library learning mechanism is doing something qualitatively different from what LLMs do — it’s discovering reusable abstractions that compress across tasks, not just memorizing solutions. The sort-list example is striking: the final program uses 5 function calls with the learned library vs. 32 with base primitives, and the base-primitive version would take 10^72 years of brute-force search. The compression isn’t just convenience — it’s what makes harder problems reachable at all. This is more like how mathematicians develop notation (inventing the integral sign, Leibniz notation) than how neural nets learn.
Biggest Questions
- What would an efficient version of this look like? i.e., how would we do both the compression step and the program generation training step?
- Program generation would likely be with LLMs
- The library learning mechanism is doing something qualitatively different from what LLMs do — it’s discovering reusable abstractions that compress across tasks, not just memorizing solutions. The sort-list example is striking: the final program uses 5 function calls with the learned library vs. 32 with base primitives, and the base-primitive version would take 10^72 years of brute-force search. The compression isn’t just convenience — it’s what makes harder problems reachable at all. This is more like how mathematicians develop notation (inventing the integral sign, Leibniz notation) than how neural nets learn.
Key Questions
- What would a practical version of this look like?
- It feels like the library itself is ever-expanding, and the model is always fed the entire library
Humanis
- Refactor
- What would be the most fundamental input?
- General.
- CPUs vs GPUs
- 200,000 GPUs
- DreamCoder on it
- Simeon
- Nodes
- Node to one communication issue
- The newton law learning
- Trained on data which is data that is perfectly generated from the laws themselves
- DreamCoder
- Penalize distance
- Sample of programs in the library
- Probability of sampling
FDFDS
- 200k GPUs
- Start learning Newton’s law
- Stuck