Link: Mastering Atari with Discrete World Models, Hafner et.al., 2021
Overview:
Paper gives a new, state-of-the-art model-based RL agent, meaning it learns abstractions about the dynamics of its environment instead of just the states / rewards.
Recurrent State-Space Model Architecture:
RSSM is a model used for model-based RL to model different parts of a partial-observable markov decision process.
Let
- $x_t$ represent observations
- $z_t$ represents the inferred state of the environment
- $h_t$ roughly represents memory of previous states / observations, and is used as part of an RNN
Then the model components are:
- Recurrent model: $h_t = f_{\theta}(h_{t-1}, z_{t-1}, a_{t-1})$
- Representation model: $z_t \sim q_{\theta}(z_{t} \mid h_t, x_t)$
- Transition predictor: $\hat{z}_t \sim p_{\theta}(\hat{z}_t \mid h_t)$
- Observation predictor: $\hat{x}_t\sim p_{\theta}(\hat{x}_t \mid h_t, z_t)$
- Reward predictor: $\hat{r}_t \sim p_{\theta}(\hat{r}_t \mid h_t, z_t)$
- Discount predictor: $\hat{\gamma}_t \sim p_{\theta}(\hat{\gamma}_t \mid h_t, z_t)$
here each function / sampling distribution is modeled with neural networks.
To train each component, we look at:
- How unlikely each observation was according to the observation predictor
- How unlikely each reward was according to the reward predictor
- How unlikely each discount was according to the discount predictor (I’m assuming this is normally just constant)
- How close our prior distribution is to the distribution achieved by sampling $x_t$ and then sampling $z_t$ from $q_{\theta}$ which is captured by the loss function
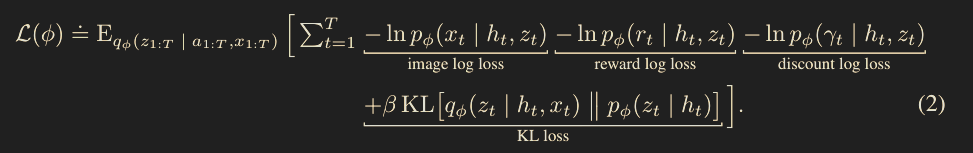
Imagination MDP:
By learning a model for the environment, our agent can imagine future trajectories and calculate their expected rewards to get an approximation for the value / Q functions. More specifically, note:
- We can keep sampling $\hat{z}_t$ according to the transition predictor $p_{\theta}(\hat{z}_t \mid \hat{z}_{t-1}, \hat{a}_{t-1})$
- We can sample rewards from the reward model $p_{\theta}(\hat{r}_t \mid \hat{z}_t)$
- We can sample discounts from $p_{\theta}(\hat{\gamma}_t \mid \hat{z}_t)$
This can be used to train a critic in an actor-critic method.
Note that since $z_t$ and $h_t$ are markovian, we have a full MDP instead of a POMDP! This is the power of having a world model, we don’t force the policy to keep track of long-horizon behavior, but instead encode that into the latent space of the world model.
Actor-Critic Training Regime:
To train the agent, we train:
- An actor $$\hat{a}_t \sim \pi_{\theta}(\hat{a}_t \mid \hat{z}_t)$$
- A critic $$v_{\theta}(\hat{z}_t) \approx \mathbb{E}_{p_{\theta}, \pi_{\theta}}\left[\sum_{\tau \geq t}\hat{\gamma}^{\tau-t}\hat{r}_{\tau}\right]$$
The full training loop:
- Sample a bunch of trajectories using real observations / rewards with policy $\pi_{\theta}$ (or some modified version of it)
- Train the RSSM model against the real data
- Freeze the world model
- Using the Imagination MDP, train the critic to better approximate state values
- Using the Imagination MDP and the critic, train the actor to maximize reward
- Repeat